Jump to main content
Menu
Home
About
Demscore
The Team
Funding
Internships
Contact
Partners
V-Dem
UCDP/VIEWS
QoG
COMPLAB
REPDEM
H-DATA
Data
Download Interface
Static Datasets
V-Dem Static Datasets
QoG Static Datasets
UCDP/VIEWS Static Datasets
COMPLAB Static Datasets
REPDEM Static Datasets
H-DATA Static Datasets
Thematic Datasets
Gender
Environment
Political Parties and Elections
Migration
Unemployment
Media
Education
Corruption
Security and Violence
Economic Development
Health
Peace
Laws and Liberties
User Support
Download Instructions
Merge Information
Demscore Handbook
FAQ
Documentation
Methodology
Reference Documents
Graphing
Research
Events
DEMSCORE Conference
DEMSCORE Conference 2026
News
Data Download
Download Instructions
Merge Information
Demscore Handbook
FAQ
Step-by-Step Instructions for
Downloading Data through DEMSCORE
Written Instructions
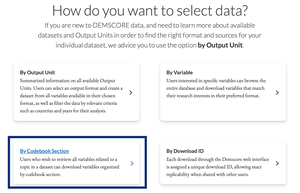
Download Instructions: by Codebook Section
Download Instructions: by Output Unit
Download Instructions: by Codebook Section
Download Instructions: by Variable
Download Instructions: by Codebook Section
Download Instructions: by Codebook Section
Video Tutorial